
Currently, AI chip designers tend to use the approach of integrating separate IP blocks next to the system CPU to handle ever-increasing demands of AI. Semidynamics has taken a different approach with the development of a unified solution that combines RISC-V, vector, tensor and Gazzillion technology that makes AI chips easier to program and scale to whatever processing power is required.
The data volume and processing demand of AI is constantly increasing and the current solution is, essentially, to integrate more individual functional blocks. The CPU distributes dedicated partial workloads to gpGPUs (general purpose Graphical Processor Units) and NPUs (Neural Processor Units) and manages the communication between these units.
Moving the data between the blocks, however, creates high latency. It is also hard to program with three different types of IP blocks each with their own instruction set and tool chains. In addition, non-programmable, fixed-function NPU blocks can become obsolete even before reaching silicon due to the constant introduction of new AI algorithms.
Consequently, an AI chip being designed today could easily be out of date by the time it is silicon in 2027 as software is always evolving faster than hardware.
Commenting Roger Espasa, CEO of Semidynamics, said, “The current AI chip configuration is inelegant with typically three different IP vendors and three tool chains, with poor PPA (Power Performance Area) and is increasingly hard to adapt to new algorithms.
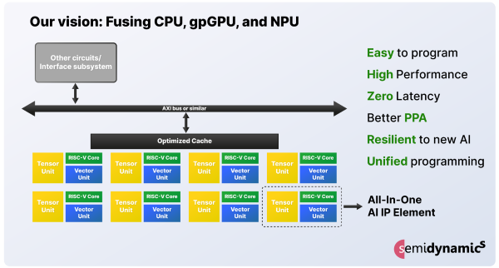
“We have created a completely new approach that is easy to program as there is just the RISC-V instruction set and a single development environment. Integrating the various blocks into one RISC-V AI processing element means that new AI algorithms can easily deployed without worrying about where to distribute which workload. The data is in the vector registers and can be used by the vector unit or the tensor unit with each part simply waiting in turn to access the same location as needed.”
According to Espasa, there is zero communication latency and minimised caches that lead to optimised PPA but, more importantly, it can be easily scaled to meet greater processing and data handling requirements.
Semidynamics has combined four of its IPs together to form one, fully integrated solution called the ‘All-In-One AI’ IP processing element. This has a fully customisable RISC-V 64-bit core, Vector Units (as the gpGPUs), a Tensor Unit (as the NPUs) and the Gazzillion Unit to ensure huge amounts of data can be handled from anywhere in the memory without suffering from cache misses.
As a result, there is just one IP supplier, one RISC-V instruction set and one tool chain making implementation significantly easier and faster with reduced risk. As many of these new processing elements as required to meet the application’s needs can be put together on a single chip to create a next generation, ultra-powerful AI chip.
“I believe we have established a completely new way to architect ever more powerful chips that will enable AI to overcome the shortcomings of the current state-of-the-art designs,” said Espasa. “Our integrated, All-In-One AI processing elements create a scalable solution that will be at the heart of a whole new generation of ultra-powerful AI chips which will be accessible to everyone. By using our new Configurator tool, they can create the appropriate balance of Tensor and Vector units with RISC-V control capabilities in the processing element.
“The RISC-V core inside our All-In-One AI IP provides the ‘intelligence’ to adapt to today’s most complex AI algorithms and even to algorithms that have not been invented yet. The Tensor provides the sheer matrix multiply capability for convolutions, while the Vector unit, with its fully general programmability, can tackle any of today’s activation layers as well as anything the AI software community can dream of in the future. Having an All-In-One processing element that is simple and yet repeatable solves the scalability problem so our customers can scale from a 1/4 TOPS to hundreds of TOPS by using as many processing elements as needed on the chip. In addition, our IP remains fully customisable to enable companies to create unique solutions rather than using standard off-the-shelf chips.”





