
Commercially deployable AI compute has enabled applications from advanced driving assistance to medical imaging to take exciting steps forward and has driven the development of new, optimised architectures including highly parallelized structures in programmable devices.
With the growing adoption of AI in autonomous systems that must deliver real-time responses and determinism, we’re seeing intelligence moving to edge applications in order reduce latency, enhance mission-critical reliability, and increase data privacy.
However, intensive edge-AI compute comes with a number of challenges whether that’s power consumption, thermal constraints or ensuring human safety. Moreover, as well as handling AI processing locally, an industrial robot or autonomous drive system must also manage communications, safety mechanisms, handle input-data streams from multiple sensor channels and manage interactions with other peripherals like a display. This calls for hardware architectures that enable whole-application acceleration.
In the automotive sector, current advanced autonomous-drive systems in today’s market are typically Level 3 (SAE J3016) systems and are already at a high level of complexity, with multiple sensors. The next generations of driver assistance systems and, eventually, self-driving vehicles, will require the integration of yet more sensing channels for contextual awareness while also demanding increased compute, lower power, smaller footprint, and reduced bill of materials.
In industrial robotics, on the other hand, AI allows powers like pattern recognition to assist fast and accurate picking, placement, and inspection. Working in unstructured environments, tomorrow’s robots must analyse and anticipate the movements of nearby humans to maximise safety as well as productivity. Real-time response and determinism, managing sensors for contextual awareness, motion control, positioning, and vision, will be mission critical as well as safety critical.
Another area of interest is UAVs, which are a high-growth opportunity in commercial and defence markets. Generally, vision-based AI is key to autonomous operation, dependent on real-time image recognition and object classification for optimising navigation paths. Defence-related applications are adopting AI-augmented tactical communications with techniques such as “human-in-the-loop” based on machine learning to assist decision making and also use advanced cognitive RF to autonomously self-reconfigure for any frequency band, modulation, and access standard, leveraging AI to adapt and learn.
More than the AI processing, dealing with multiple sensing modalities such as radio, radar, vision, and others needed for detailed situational awareness is potentially the greatest bottleneck to performance.
Accelerating Edge AI
The processing architectures that have delivered high-performance AI in the cloud can be harnessed to enable these new intelligent edge devices. Xilinx’s Versal brings various differently optimised processors onto one chip, with memory, peripherals, and platform-wide high-bandwidth interconnect.
A key innovation is the AI-Engine array (Figure 1), which brings together hundreds of vector processing units (VPUs). Each VPU has RAM located directly alongside, allowing low-latency access across a wide-bandwidth interface. Neighbouring VPUs can share this RAM, creating a cache-less hierarchy that can be flexibly allocated and an interconnect with bandwidth equivalent to 10s of terabytes per second links the VPUs. Together, the vector core array, distributed memory, and flexible interconnect create a software-programmable architecture that is hardware adaptable and delivers high bandwidth and parallelism with low power and latency. Signal-processing throughput is up to ten times greater than GPUs for accelerating cloud AI, vision processing, and wireless processing.
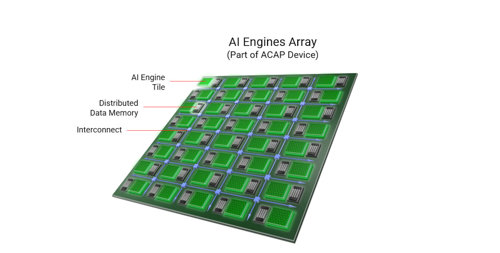
Figure 1: The AI Engine array features tightly coupled distributed RAM
Versal AI Edge adaptive platforms can further optimise this architecture to meet the special needs of intelligent edge devices. In particular, the AI Engine-ML (Figure 2) is a variation of the AI-Engine, optimised for machine learning.
Compared to the standard Versal AI Engine, AI Engine-ML natively supports faster and more efficient handling of INT4 integer quantization and BFLOAT16 16-bit floating-point calculations common to machine-learning applications. Also, extra multipliers in the core have doubled INT8 performance. In addition, extra data memory further boosts localisation and a new memory tile provides up to 38 Megabytes across the AI-Engine array with high memory-access bandwidth - machine-learning compute has been increased four-fold and latency halved.
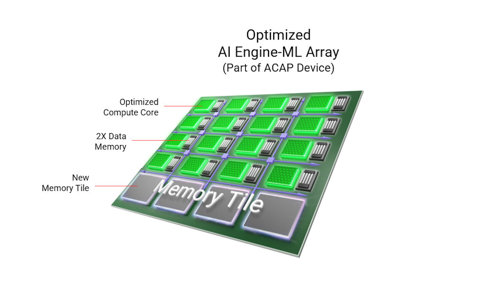
Figure 2: AI Engine-ML for efficient handling of machine-learning applications at the edge
The AIE-ML can handle heterogeneous workloads as well as machine learning, while the existing AI Engines’ native 32-bit processing accelerates arithmetic such as INT32 and FP32 and maintains balanced performance across diverse workloads.
Interactions with memory represent a notorious performance bottleneck in processing systems, however, this edge-focused platform adds accelerator RAM, a 4MB block with a high-bandwidth interface that is accessible to all processing engines on the chip. This can save AI-Engines storing critical compute data from neural networks in DDR RAM during high-speed inference, thereby reducing power consumption and latency, and lets the real-time processors keep safety-critical code on-chip for lower latency and safer operation.
Designers can use these devices with their preferred tools, languages such as C or Python, and AI frameworks like Caffe, TensorFlow, and Pytorch. There are large numbers of AI and vision libraries to run on Versal Adaptable Engines or Intelligent Engines, support for Robot Operating System (ROS) and ROS2, and support for safety-critical design with RTOSes such as QNX, VxWorks, and Xen, catering for functional safety standards.
With its distributed architecture, the family is also scalable and can address applications from edge sensors and endpoints to CPU accelerators. Devices scale from eight AI Engines, drawing less than 10W total power, to over 300 AI Engines that deliver over 400 TOPS of INT4 throughput, in addition to Adaptable Engines and DSP Engines.
Whole-application acceleration
To understand the effects of all this on system performance, take the ADAS example described earlier, implemented on three Zynq devices. A single mid-range Versal AI Edge IC can host the same application and deliver 17.4 TOPS, more than four times the processing throughput, to handle increased camera definition and extra video channels within a comparable power budget of 20W. The IC and associated external circuitry occupy also occupy 58% less area.
The various workloads can be assigned appropriately among the available engines, using the Adaptable Engines for sensor fusion and pre-processing including time-of-flight ranging, radar and lidar point-cloud analysis, vision image conditioning, environment characterization, and data conditioning such as tiling. Simultaneously, the Scalar Engine can focus on decision making and vehicle control.
A further advantage is that the hardware configuration can be changed on the fly, within milliseconds, to let one device handle multiple functions. An automotive application may load a hardware configuration optimised for features such as lane-departure correction or anti-collision during highway driving, to be exchanged for a new configuration such as park-assist as the vehicle enters an urban area. After parking, another functionality could be loaded.
Developers can also establish a highly optimised hardware implementation of their target application, perhaps bringing together solutions for LiDAR and radar sensing, or a front camera, on the same platform, each with custom AI and sensor-processing capabilities. This cannot be achieved with CPUs and GPUs. Moreover, as today’s automotive industry imposes rapidly changing requirements on automakers, the adaptive platform can be quickly changed over the air, similar to applying a software update.
Safety- and Mission-Critical Design
In industrial control and robotics, the Adaptable Engines can handle tasks like perception, control, networking, and navigation, while AI-Engines can augment control for dynamic execution and predictive maintenance and Scalar Engines handle safety-critical control, user-interface management, and cybersecurity.
In multi-mission and situationally aware UAVs, developers can use the Adaptable Engines for sensor fusion, waveform processing, and signal conditioning. The Intelligent Engines can focus on low-power, low-latency AI and signal conditioning for navigation and target tracking, as well as waveform classification for cognitive RF and spectrum awareness. The Scalar Engines handle command and control and can run in lock-step to ensure safety and security.
A single Versal AI Edge device can support multiple inputs including radio communication, navigation, target-tracking radar, and electro-optical and infrared sensors for visual reconnaissance (Figure 3). Intensive sensor fusion like this would be difficult to do in a typical machine-learning processor.
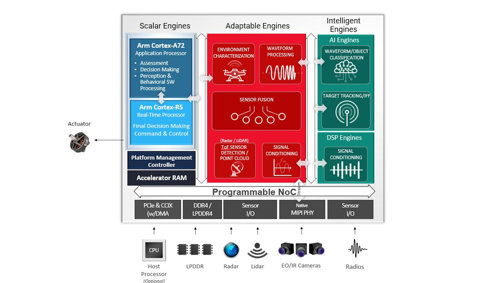
Figure 3: Integrated control of situationally aware UAV
AI has a central role in enabling the next generations of autonomous systems. Safety and performance depend on real-time, deterministic compute, although size, weight, and power are tightly constrained. Adaptive compute, proven in cloud AI applications, addresses the challenge with edge-optimised machine learning and whole-application acceleration.
Author details: Rehan Tahir, senior product line manager and Ehab Mohsen, product marketing manager, Xilinx





