
The focus in design has turned to how to sift through large quantities of data, using long-distance relationships in information. In contrast to more conventional algorithms that often work on highly localised data streaming through the system, machine learning puts much more pressure on memory transfer rates and the energy cost shuffling data from bulk memory in and out of processors.
One option is to avoid moving the data. Instead, you bring the computational engines into the memory arrays themselves. Although it was Professor Bill Dally’s group at Stanford University that provided solid evidence for memory access being a major contributor to the energy cost of computing, nVidia’s chief scientist is not a believer in the idea of putting compute into memory to try to reduce that cost. He argues that locality has not gone away completely simply because the data sets have exploded in size.
In keynote speeches at a string of conferences last year, Dally said that it is easy to lose sight of the fact that the most costly accesses to memory in terms of energy are relatively infrequent even in machine-learning applications.
“The gains are assuming you have to read memory for every op [operation] but you don’t. You do a read from memory maybe once every 64 ops. With a reuse of 64 or 128, the memory reference [energy] is actually in the noise,” he said in a keynote at the SysML conference.
Chairing a session dedicated to in-memory computing research at the Design Automation Conference (DAC) in Las Vegas earlier in the summer, University of Michigan assistant professor Reetuparna Das agreed with Dally’s assessment on energy. “The biggest advantage of compute in memory is bandwidth, not so much energy in my opinion.”
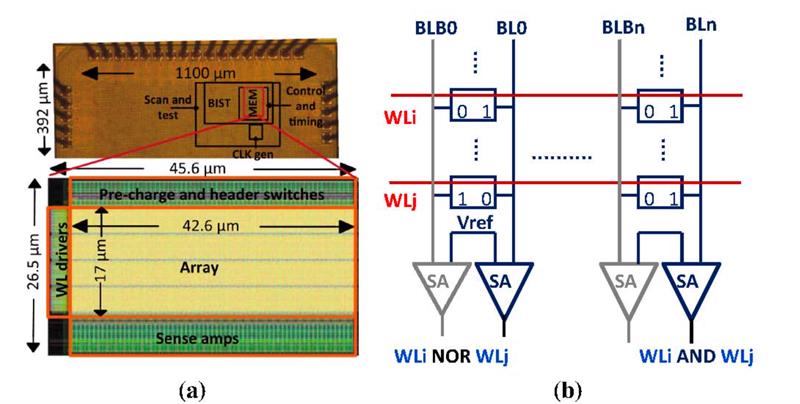
Above: Prototype test chips and a SRAM circuit for in-place operation
Bandwidth was the target of attempts at in-memory compute that some manufacturers tried two decades ago. In 1994, Sun Microsystems made a brief foray into memory design with the help of Mitsubishi Electronics America to create what they called “3D RAM”. This put some of the processing needed for 3D rendering into the framebuffer memory itself, mostly performing simple pixel-by-pixel comparisons if one object in the space occludes another. This removed the need for the graphics controller to read those pixels itself, freeing up bandwidth on the bus. At the time, the economics of memory did not favour the development of highly customised versions except in markets where the price premium was acceptable.
Move to customisation
The economic argument is now shifting in favour of customisation as traditional 2D scaling in DRAM comes under pressure and memory makers look to novel architectures such as magnetic (MRAM) or resistive (ReRAM) technologies.
“These new memories will become the basis for in-memory computing,” says Kevin Moraes, vice president at Applied Materials.
Expecting the memories to be incorporated into SoC devices, such as low-energy sensor nodes, Applied is working more closely with specialised start-ups such as Crossbar and Spin Memory to develop production tools for fabs. “Now we do a lot of work hardware and software co-optimisation as well as manufacturing,” adds Moraes.
One common factor of in-memory computation engines is that, in contrast to Sun’s 3D RAM, many of the candidate technologies can be found on the boundary between analogue and digital computation. For start-ups such as Mythic, analogue processing within the array allows the rapid processing of data at a relatively low resolution: typically 8bit or lower. To support this, data values are converted to analogue values using DACs before being fed into the memory array for processing.
The contribution of Das’s group at Michigan to in-memory computing does not rely on such heavy customisation of the interfaces to the memory, an attribute she says could help it gain traction. It was also a requirement from Intel, a sponsor of the work in order to keep implementation cost down. The Neural Cache is aimed squarely at machine-learning applications and makes use of simple logic operations to process data. Another key difference to other proposals is that it makes use of more expensive memory cells – those used in high-speed caches – than those aimed at bulk memory technologies.
In operation, the Neural Cache borrows a concept that drove computation inside FPGAs before they acquired hardwired digital signal processing (DSP) cores: bit-serial computation. The advantage of bit-serial arithmetic is that it can use simple AND and NOR operations rather than logic-intensive multipliers. Sense amplifiers detect the logic state of pairs of complete wordlines when they are activated. The main addition to the memory is a transpose unit that rearranges data so that the values can be pumped straight into the array.
Although bit-serial operations suffer from high latency, Das claims the Neural Cache can win out against high-end processors because it can do many operations in parallel. For example, an 8KB SRAM can operate on 256 elements at once because it has 256 wordlines and 256 bitlines. The group proposes using something like the last-level cache of a processor such as Intel’s Haswell, which contains more than 4000 of those 8KB SRAM arrays. In doing so, more than a million elements could be processed in parallel at more than 2GHz. “It only adds a 3.5 percent overhead to a Xeon and is as programmable as a GPU, which helps make it futureproof for emerging algorithms,” Das claims.
Linear algebra
Although machine learning drives most of the current crop of in-memory computing start-ups, Engin Ipek, associate professor at the University of Rochester says other matrix-oriented algorithms can benefit. Ipek’s work has focused on linear algebra and, similar to the cache-based work at Michigan, avoids the need to handle intermediate values even on ReRAM arrays.
The practical problem with ReRAM for analogue computing is that its signal-to-noise ratio is very low.
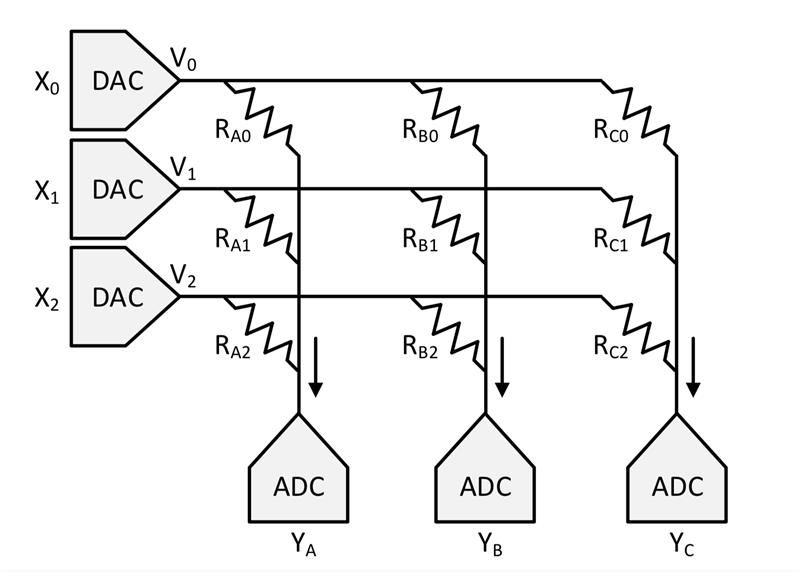
Above: Data values are converted to analogue values using DACs before being fed into the memory array for processing
“There are no ReRAM cells today that give you 8bit or even 2bit resolution reliably. But you don’t necessarily need more than 1bit. The nice thing about linear algebra is that it’s linear,” Ipek says. “You can split the execution into bit slices and perform bit-wise matrix calculations.”
Even with 1bit devices, a potential problem with novel memories such as memristive arrays based on ReRAM or phase-change cells is their error rate.
“We can’t use error-correcting codes because with that you have to read then correct then compute. With this architecture but the time you’ve corrected you’ve performed the calculation,” Ipek says.
To deal with errors, the data itself is pre-processed using AN-codes that makes it possible to perform the addition operations of bit-serial arithmetic and correct single-bit errors once the computation is complete.
Although the technique is focused on linear algebra, Ipek says it could be extended to sparse-matrix problems found in many compute problems, which include machine learning. “Many matrices in real-world applications are sparse,” Ipek says, noting that for compatible algorithms the approach consumes ten times less power than when run on a GPU for highly parallelised data.
The focus on these architectures remains one where data needs to be imported into an accelerator – one that happens to rely on memory architecture to perform calculations – rather than running the application in situ. Shekhar Borkar, senior director of technology at Qualcomm says this may prove to be the weakness of in-memory architectures. Data-intensive applications need to work with such large quantities of memory that the cost of adding computation to the entire array becomes prohibitive.
Unless the data has to move through the array on its way somewhere, which happens with storage devices and caches, the idea of keeping data in one place and operating on it may prove to be short-lived.
Devices that simply use memory as a processor for streaming data may have more success as long as workloads continue to favour highly parallelised single operations.
At the DAC panel, a Facebook research scientist summed the situation up: “These techniques have promise but they are still coming from behind.”





