
Geoffrey Burr, principal research staff member at IBM Research’s lab in Aldmaden, claimed at the Linley Spring Processor Conference earlier this year that the energy consumed by the GPUs typically used to train a deep neural network (DNN) like ResNet-101, which at 44.5 million trainable parameters is today not particularly large, could provide a typical US home with energy for two weeks.
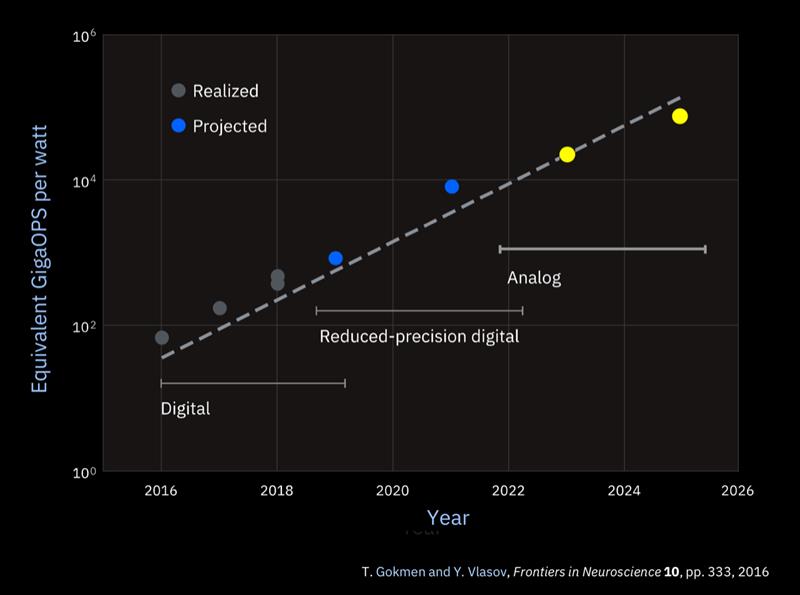
As model size continues to spiral upwards, the number of floating-point operations needed to train them doubles every three-and-a-half month. "That is an unsustainable curve unless you do significant hardware and software innovation."
Though training needs the most energy while it’s running inferencing, when the models are deployed, presents a major problem, not least because training only runs once in a while. Inferencing in embedded applications such as autonomous vehicles will have to run non-stop.
There is one clear target for energy reductions, though.
Elisa Vianello, embedded AI programme director at CEA-Leti, says memory accesses dominate the energy equation. “Moving data to and from the processor requires 90 per cent of the energy,” she says, pointing to a need for novel architectures that can cut the cost.
During his firm's autumn processor conference at the end of last month, Linley Gwennap, principal analyst and president of the Linley Group, noted: “To reduce the power of moving data across the chip, some vendors are implementing in-memory architectures to either move the compute close to the memory or move compute into the array itself and use memory cells to perform certain computations.”
Some suppliers are achieving this proximity using architectures that either are FPGAs or resemble them in the way they distribute memory blocks through an array of hardwired and programmable logic blocks. Although there is still a process of back and forth with the data values as they move in and out of arithmetic logic units (ALUs), the load capacitance and resulting energy consumed along those paths is a fraction of that needed to send words over even an on-chip bus.
IBM and a number of start-ups see the opportunity to go much further and push computation into the memory cells themselves, a move that is somewhat easier for inference today than for training.
Above: Analogue processing could prove to be more energy and area efficient
Accuracy and reliability
One common observation of deep-learning pipelines when you move from training to inference is a massive reduction in the accuracy and even reliability needed for calculations.
Training relies on the ability to compute gradients for long chains of neuron weight that can be extremely small. This leads to the need to use floating-point arithmetic because of its ability to maintain precision over a large dynamic range, just as long as the coefficients in each calculation are reasonably close to each other.
Today, in the digital domain, 8bit integer arithmetic can handle many of the operations needed without degrading quality more than a few percentage points. Some work has indicated the compression can go further by trimming some weights down to 4bit, ternary or even binary. Energy can easily fall by an order of magnitude.
“We need a change in the compute paradigm,” Burr says. Alongside work on approximation in digital IBM is looking at processing in the analogue rather than the digital domain. “We are working on it because it could offer a hundred-fold improvement in energy efficiency.”
Whereas even at 8bit resolution a fast multiplier needs hundreds of gates, matrix multiplication in the analogue domain can be handled using little more than a group of resistors and bitlines.
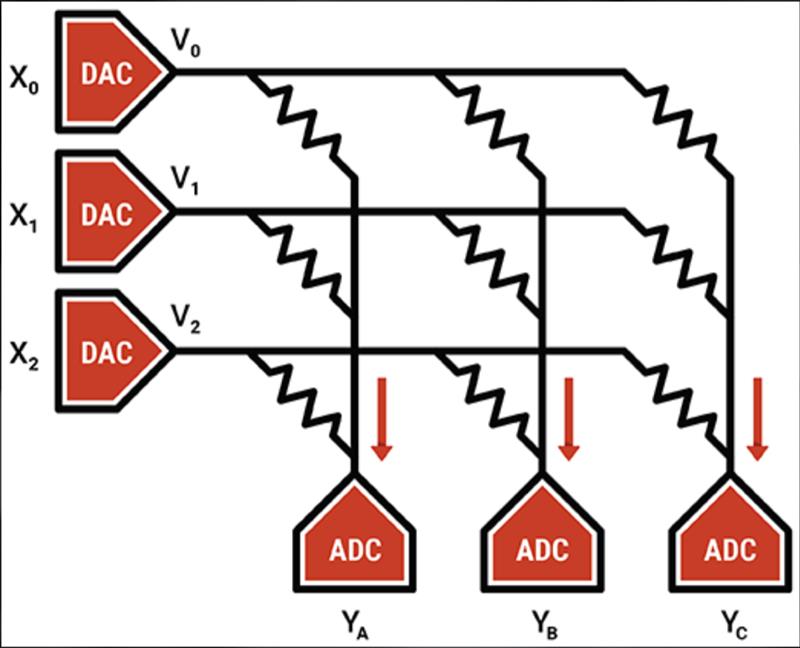
“You can use what we call resistive processing unit: encode the neuron weights into the conductances you find on the crossbar array,” Burr explains.
Non-volatile memory technologies readily provide the variable resistances needed for analogue arithmetic. IBM is working on phase-change memories on experimental devices today and may switch to resistive RAM in the future. Flash is a more mature option. A start-up that is sampling to a small group of advanced customers and which expects to go into production later on in 2021 is Mythic AI, using a 40nm embedded flash memory that started at Fujitsu and which is now owned and supplied by UMC.
With each individual cell operating as a multiplier, millions of parallel operations become feasible. Instead streaming weight coefficients in and out of ALUs together with the sensor data, those weights can sit inside the multi-megabyte non-volatile memory array permanently. Those weights only change when the model needs to be updated, which helps overcome long-standing issues with the write endurance of most non-volatile memory technologies.
Above: Mythic uses an array of Flash memory transistors to make dense multiply-accumulate engines
Problems need addressing
Though analogue processing could prove dramatically more energy and area efficient as a result the path to making it happen is far from free of problems.
“A lot of the non-volatile memories that are being proposed for deep learning are plagued with a lot of variability and stochasticity,” says IBM Research scientist Robert Bruce, though it is possible to trade density for greater fault tolerance he adds.
The need to deploy large numbers of digital-to-analogue and analogue-to-digital converters that need to operate with greater levels of accuracy and resolution than conventional memory sense amplifiers come with their own yield and variability issues.
Tim Vehling, senior director of product development at Mythic, says their core array macro calls for 27,000 working data converters. “A lot of our IP is how we test. We use redundancy all over the place and we have pretty advanced calibration techniques that we do at build time and also use at runtime.”
Although error correction and redundancy can overcome many of the issues, there is a level of uncertainty in the analogue computations that is not encountered in digital implementations that reduces model accuracy. But this is not necessarily a permanent loss. “When we port a network from a digital model we do have to do some redesign. We do retrain the model to accommodate the analogue effects,” Vehling says.
The retraining for analogue AI devices will typically take place on digital servers because of their lower resolution. Though Bruce says inference is the near-term goal for IBM's technology, the aim at the computer giant is to have analogue take on more of the heavy lifting in training so that it can put the chips into server blades and reverse the staggering growth in energy consumption. That will also remove the need to adjust training for analogue inference though it will take some breakthroughs in training techniques to make work.
Using a heavily customised combination of SRAM and converters, Ambient Scientific expects to be able to push training into edge devices. Though the company is secretive as to how it works until a clutch of key patents are approved, Ambient CEO GP Singh claims their architecture will support resolutions all the way from 4bit to 32bit. The throughput of the array is expected to be 4.3TOPS/W at 8bit resolution, which is close to Mythic's claim for their flash-based array. That throughput/power ratio drops four-fold for each doubling in resolution as the converters need to take more time and handle more charge on each calculation.
A key question is whether the overall energy savings made possible by the shift to analogue will be enough to carve out an advantage over highly tuned digital-only implementations. Arm claims its Ethos-N77 used with distributed SRAMs can achieve 5TOPS/W, as long as it is implemented on leading-edge CMOS that will generally incur a higher wafer cost than the older processes used in the analogue-oriented designs and tend to be used on large models that run in an embedded-Linux computer. The characteristics of analogue may push it closer to the edge.
One area where analogue is likely to have an advantage is in always-on sensing where a more limited AI model that runs at leakage-power levels watches for events before triggering a more capable and power-hungry back-end.
“There are naysayers who say it doesn't work: that there's no way analogue could have the accuracy,” Vehling argues. “We are showing it does work. It's an exciting time: we are starting to see a different way to do compute.”





