
This solution enables efficient integration of large-scale chiplet-based computing systems such as high-performance computing (HPC) and big-data applications.
To scale out the architecture, to meet the needs of high level performance in HPC and big-data technologies, existing techniques using 3D integration and chiplet partitioning with large-scale interposers have been designed for building large modular architectures and achieving cost reduction in advanced technologies by known-good-die (KGD) strategy and yield management.
Large-scale interposer techniques for chiplet integration have been fabricated using various technologies, such as 2.5D passive interposers, organic substrates, and silicon bridges, but these technologies lack flexible long-distance chiplet-to-chiplet communications to connect a larger number of chiplets. They also lack smooth integration of heterogeneous chiplets, and the easy integration of less-scalable functions such as tightly coupled power-management solutions, analogue functions and IO IPs.
In the framework of IRT Nanoelec, CEA-Leti and List have succeeded in overcaming these limitations by introducing an active-interposer technology that enables integration of some active CMOS circuitry on a large-scale interposer. They have also managed its implementation on a STMicroelectronics process using a 3D CAD tool design flow from Mentor Graphics, a Siemens business.
The active interposer integrates:
- voltage regulators fully integrated without passives for efficient power management of the 3D-stacked chiplets
- flexible system interconnect topologies between all chiplets for scalable cache-coherency support
- energy-efficient 3D-plugs for dense high-throughput, inter-layer communication, and
- a memory-IO controller and the physical layer (PHY) for socket communication.
The results of this work have been presented at ISSCC 2020.
“This is a breakthrough in terms of system-and-architecture integration, achieved all the way from the architecture concept down to a silicon prototype,” said Pascal Vivet, lead author of the paper. “In addition, 3D technology and associated design techniques now are available to implement large-scale computing systems, offering for the first time a chiplet-based 96-core computing architecture.”
According to Vivet, the active interposer integrates flexible and distributed interconnects, 3D-plug communication IP, and power management IP to offer overall a fully integrated and energy-efficient many-core computing architecture. As a result, users will get more GOPS at the same power budget and will benefit from an increased memory-computing ratio along the memory hierarchy. .
“Active interposer technology will also be an enabler to integrate heterogeneous functions,” Vivet said. “Chiplet-based ecosystems will deploy rapidly in high-performance computing and various other market segments, such as embedded HPC for the automotive and other sectors. “The active interposers also create opportunities to revisit system partitioning and implement extra functions at the interposer level. The ecosystem collaborated to build future 3D technology platforms that will benefit from CEA technologies to create major differentiators in future work.”
Future work will address die-to-wafer hybrid bonding technology, which offers denser 3D interconnects with better electrical, mechanical and thermal parameters, and allows ultra-dense, low-energy parallel interfaces. For the longer term, CEA-Leti is also investigating photonic-interposer technology as a 3D-based photonic chiplet approach, offering low-latency, high-bandwidth, energy-efficient photonic communication.
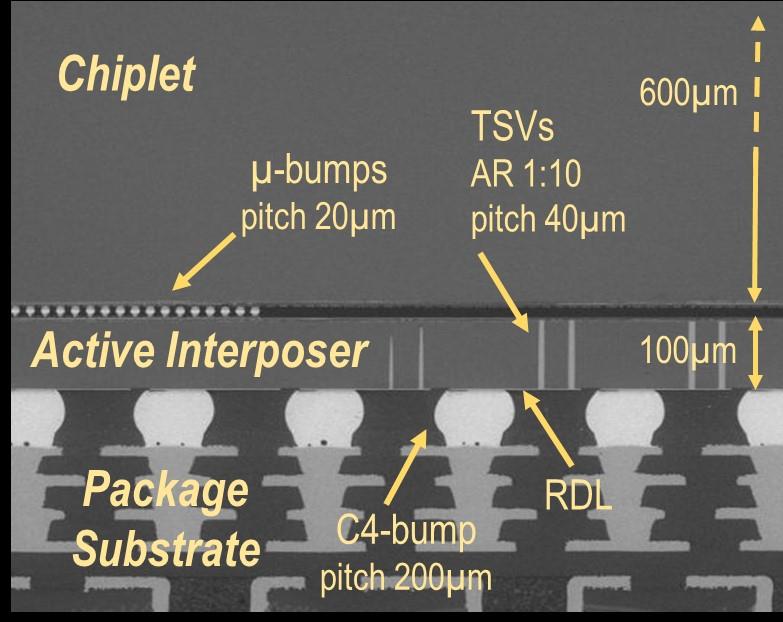
The prototype’s 96 computing cores have been organised in six chiplets in 28nm FDSOI, CMOS node, which are 3D-stacked in a face-to-face configuration using 20µm pitch micro-bumps onto an active interposer embedding through-silicon vias (TSVs) in a 65nm technology node.
The overall system architecture offers a fully scalable distributed cache-coherent architecture between all the chiplet computing tiles, which are interconnected through the active interposer. The innovative cache-coherent architecture allows easy software deployment through a hierarchy of caches, for full system scalability up to 512 cores.





