
Today’s projections bear Feynman out. According to Prof Milutinovic, a double-precision floating-point multiplication performed on a computer built in 2018 should consume 10pJ. But writing the result to memory costs 2000pJ.
Professor Mark Horowitz of Stanford University said at last year’s Design Automation Conference: “You quickly realise that, in a modern microprocessor, most of the energy goes into the memory system. I really don’t want to read and write the DRAM because it uses 1000 times more energy than accessing the data locally.”
Power is a problem that has become more than noticeable in data-centre applications. Professor Jason Cong of UCLA says: “Data-centre energy consumption is now a very big deal. We are looking at having to build 50 additional large power plants by 2020 to support them.”
But some of the hungriest applications that are now running in data centres are best placed to accept the Feynman fix. The simple answer to slashing energy usage is to avoid shuffling data in and out of main memory and, even within a chip, to minimise the distance it travels. It works out to be about 5pJ per millimetre.
In reality, even caches are bad news because of the power needed to keep multiple word and bit lines in a state of readiness. ARM’s plans for its DynamIQ architecture include the ability to power down regions of memory selectively when not being used even for short periods and so remove a source of high current leakage. The problem is that von Neumann computer architectures are designed to repeatedly move data in and out of memory, whether register files, caches or main memory.
One option is to move to a dataflow architecture in which arithmetic units pump data through pipelines to their neighbours. Although computer scientists have proposed a shift to dataflow processors for several decades, software has stood in the way of making much progress outside of specialised applications, such as the systolic arrays used in military radar. These systems often use FPGAs because of the way they allow onchip DSP cores to connect to each other directly.
Similar systems are now used in servers deployed by customers in financial, medicine and engineering. Prof Multinovic has worked closely with UK-based Maxeler Technologies, which has built FPGA based dataflow accelerators for a decade.
A further boost for dataflow comes from artificial intelligence. The idea of machine learning is compelling, not just for embedded applications such as self-driving cars, but also in enterprise applications ranging from financial analysis to interactive chatbots for customer service.
Derek Meyer, CEO of Wave Computing, claimed at an event in March: “When it comes to natural language processing and bots, we have seen a lot of growth in that area. Machine learning will affect a lot of business-process optimisation applications.”
The advantage of machine learning to these customers, Meyer says, is the belief that many interactions are too difficult to capture with static rules encapsulated in lines of procedural software. “No code is the best code,” he says.
The common thread that links machine learning to data-analytics applications written in languages such as Hadoop is the idea of a computational graph.
A computational graph is a representation of a composite function as a network of connected nodes, where each node is an operation/function. While machine-learning tools build a graph dynamically by analysing the data and attempting to fit it into a model, more conventional Hadoop programs build the graph explicitly.
Rather than shoehorning information into densely packed regular matrices and tables, the applications steer data through an often irregular graph that can straddle huge volumes of memory which are extremely difficult to cache effectively. The data in a convolutional neural network similarly flows from virtual neuron to neuron and, in many applications, in feedback loops. The dataflow architecture fits the concept of computational graphs readily: a compiler can chop the graph into sections and map it directly onto its network of arithmetic units.
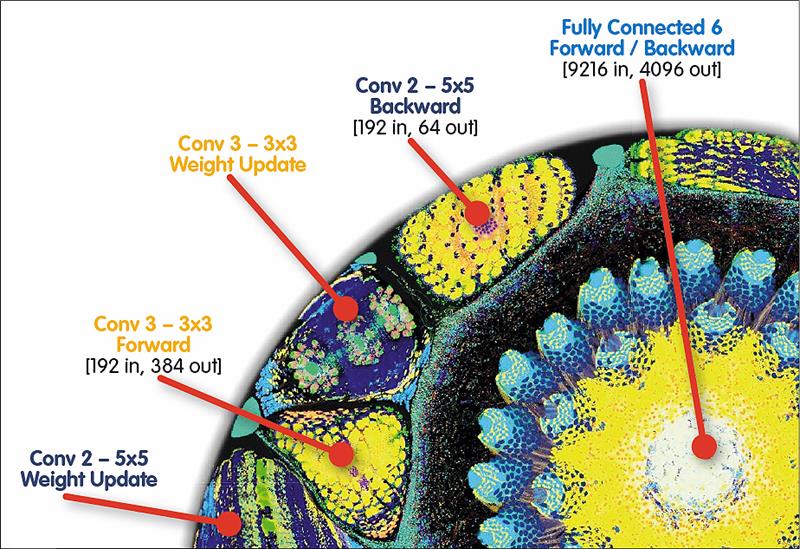
Figure 2: The graph for the full forward and backward training loop of AlexNet, a deep neural network which uses convolutional and fully connected layers as its building blocks
Matt Fyles, a software engineer with Bristol based Graphcore, says the Poplar compiler that targets the company’s processor array – set to be unveiled later this year – ‘builds an intermediate representation of the computational graph to be scheduled and deployed across one or many intelligence processing units’.
California-based Wave Computing says its architecture is based on a hybrid between FPGA and conventional manycore processors: the coarse-grained reconfigurable array. The Wave architecture organises small processors into clusters that talk to each other over an AXI4 interconnect, similar to that used by conventional ARM-based multicore processors.
Processing elements inside the cluster do not write to registers, but simply forward data to neighbours using routing defined at compile time. The compiler remaps the interconnect for each new task or program. The arithmetic units can be split into narrower 8bit or 16bit segments instead of a full 32bit word. Work by a number of companies in machine learning in particular has shown that many applications do not need full numeric precision and this is exploited by software environments such as Google’s Tensorflow.
There is a halfway house between the dataflow architectures favoured by Maxeler and Wave – giving conventional processors better control of data flowing in and out of memory. This is the approach taken by Cadence subsidiary Tensilica and CEVA.
The Cadence and Ceva architectures use very long instruction word (VLIW) processor pipelines so many data elements can be processed at once. But, rather than work on regular 2D arrays where the data is contiguous, a scatter-gather direct memory access (DMA) controller pulls information into a local scratchpad from different parts of main memory. The processor works on the data while it is cached before the DMA finally writes it back out.
To reduce the overall workload, Cadence has worked on pruning graphs in software to remove connections that have little influence on the final output.
Cadence senior architect Samer Hijazi says architectures may become more hardwired ‘as algorithms freeze and the evolution of the technology slows down – but not today’.
A longer term option is to move processors into memory to reduce the distance travelled by data. “It’s a nice idea,” says Hijazi, but for the near future he favours greater use of software optimisations targeting more conventional architectures, such as his company’s VLIW machines. In the meantime, those architectures seem likely to acquire more dataflow features to address the memory power problem and take advantage of a change in the way software is written – away from the procedural languages that underpinned the von Neumann era.
Forwarding networks that reroute data around the register file have long been part of deeply pipelined RISC processors. The processors on a manycore SoC may simply start forwarding results to each other, avoiding the register file altogether.





