
If it is to break into a broader range of real-time applications, such as self-driving cars and robots, AI needs to be able to work without calling for help from remote servers. Even if the connections were entirely reliable, latency is incurred by data crossing the network before it can be interpreted. AI needs to be more local, which means cutting the power demand of its algorithms.
One option is to move away from deep learning for these real-time systems, even though that has become practically synonymous with AI. Gradient descent links many of the techniques used in machine learning (ML) today. It extends from simple curve-fitting algorithms to highly complex loops and stacks of virtual neurons that underpin the video and audio recognition abilities of server-based deep-learning systems.
While the current focus is hardware optimisation for deep learning, the same techniques will often apply to other areas, such as support vector machines and Gaussian processes.
In neural networks, the transfer of data and neuron weights to and from memory dominates power consumption. Bringing data and processing power closer together makes a big difference. A further optimisation is to make the arrays smaller to limit their capacitance. At ISSCC 2017, University of Michigan researchers, led by Professors David Blaauw and Dennis Sylvester, showed a hierarchical way to bring memory and processing closer together for ML (see figs 1 and 2).
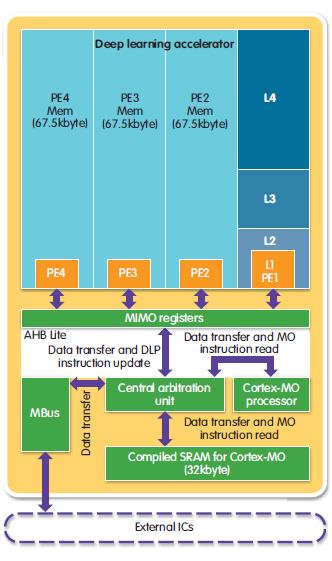
| Figure 1: A top level view of a proposed deep learning accelerator |
Small arrays for storing more frequently used data, such as input neurons, were custom designed for low-current operation and placed close to the processor. Synaptic weights, which are used less often in calculations, went into denser, more power-hungry SRAM cells that could sit further away. There, they could more afford to suffer the higher capacitance of a larger array and longer buses. The design avoided the use of caches altogether, relying on static scheduling to assign data to the right memory banks.
Some R&D teams have found it possible to reduce the arithmetic precision of a lot of neuron calculations, sometimes to as little as 4bit or 8bit for comparatively unimportant links. Some connections can be pruned completely because their contribution is relatively tiny.
A useful aspect of AI architecture, such as CNNs, is their error tolerance; the large number of individual calculations tends to average out. Whereas most digital designers work to remove the possibility of error from arithmetic circuits, those working on approximate computing accept them if savings can be made elsewhere. One option is to run circuitry much closer to its voltage threshold and accept that some neurons will not compute the right answer.
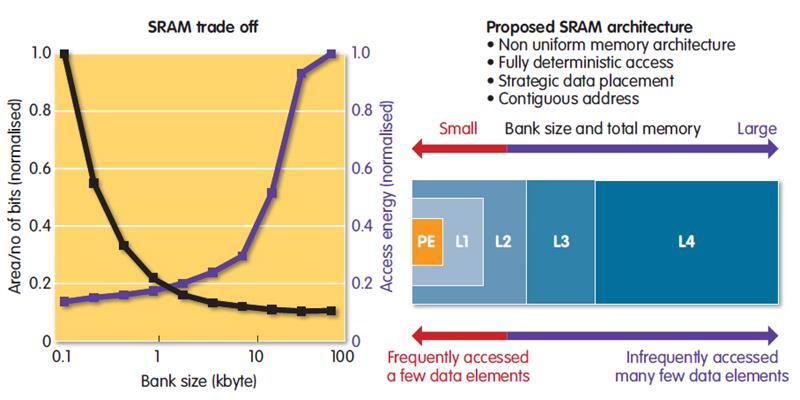
Figure 2: Small arrays placed closer to the processor could be used to store more frequently used data |
Approximate computing for ML need not be isolated to digital circuitry. On the basis that digital multiplications contribute a significant amount to overall energy consumption, Zhuo Wang and Naveen Verma of Princeton University recently developed a circuit design based on a ladder of comparators. Each comparator is twice the width of its lower neighbour: an arrangement similar to that found in a flash A/D converters. However, unlike an A/D converter, comparator gates can be switched to ground or the signal input, providing a way for the training algorithm to program thresholds dynamically. The comparator outputs are summed and produce a voltage that approximates a linear classifier. The machine-learning system they built is much simpler than a CNN, but could be trained to recognise numbers in 9x9 images, while consuming was 30 times less energy than a comparable design based on digital multipliers.
Enyi Yao and Arindam Bass of Nanyang Technological University opted to exploit the combination of randomness and analogue circuitry. They based their design, published early this year, on the extreme learning machine (ELM) design proposed by Nanyang’s Professor Guang-Bin Huang a decade ago. The ELM is based on the same multilayer architecture as used in traditional neural networks, but only the outer-layers weights are trained; neurons in hidden layers use random weights. The design simplifies training massively, yet still works for some types of problem.
Another option is for AI algorithms to use memory arrays for processing. For example, the Hopfield network is a type of neural network that operates like an associative memory. At the 2012 DATE conference, Professor Leon Chua argued the memristor – the fundamental device type he proposed in the 1970s – could be used to implement neuromorphic computing and claimed the Hodgkin-Huxley model of the synapse shows memristor-like behaviour. Other researchers, such as Professor Sayeef Salahuddin of the University of California at Berkeley, argue the thresholding behaviour often seen in biological brain activity is not just common to memristors. Devices such as spin-torque transistors, themselves derived from magnetic memories, exhibit similar effects.
Several years ago, University of Pittsburgh assistant professor Helen Li used memristors to build a neuromorphic AI. It could perform character recognition with a claimed hundred-fold greater energy efficiency compared to conventional digital processors.
Quantum computing offers an alternative path to that of trying to emulate biological brains and could demonstrate very good energy efficiency for some types of ML. Google and Microsoft have joined startup D-Wave Computing in pursuing quantum annealing as a stepping stone to full quantum computing. The inspiration for quantum annealing systems comes from a theory developed by Ernst Ising almost a century ago. He came up with the idea of a spin glass to represent a highly disordered, hot magnetic material. As it cools, the magnetic moments of the atoms in the glass align, with spins flipping up and down to try to find the lowest energy state.
A quantum-annealing machine uses qubits in place of atoms, but follows the same principle: excite a system into a disordered state and then let it settle to its lowest energy state. The hardware was designed originally for optimisation problems that are difficult to compute on digital hardware, such as the Travelling Salesman problem. The machine is pushed towards the solution by manipulating electromagnetic fields around the qubit elements.
The optimisation process also works for the curve-fitting problems used by many classical machine-learning algorithms. Researchers have used hardware such as D-Wave’s and systems based on nuclear magnetic resonance techniques to build simple machine-learning systems that can tell numbers apart.
Quantum and neuromorphic technologies could align with more complex quantum computers. Late last year, researchers from the universities of Oxford and Waterloo demonstrated a way of building quantum memristors using supercooled quantum dots that may translate to systems that operate at room temperature.
Although AI has suffered numerous false dawns, the rapid adoption of deep learning by the FANG group – Facebook, Amazon, Netflix and Google – has perhaps finally given it a permanent role in IT systems. As AI becomes more commonplace, it may be the driver behind what seem today quite exotic forms of computing. But with many avenues opening up from memory-based systems to quantum, it remains unclear which direction low-energy AI will finally pursue.





