
In August, analyst firm Gartner put generative AI at the top of the peak of inflated expectations, only slightly behind cloud-native computing.
So, assuming the technology follows the normal adoption cycle, a period of obscurity beckons before a useful form emerges in the second half of this decade. That might provide enough time for governments and legal systems to work out how to deal with the ramifications of large language models (LLMs) and their successors, both in terms of the data on which AI trained them and the outputs they generate.
As LLMs have moved from research curiosities to actual products, people and organisations who have found their works absorbed into the huge training sets have turned to the courts to limit how these models apply their intellectual property (IP). The results yield case law that affects not just the application of LLMs in art, music and content generation but in a far more diverse range of systems, right down to those that will be incorporated into embedded systems.
AI’s apparently sudden problems with copyright law took time to appear for one simple reason. Most of the teams working on the technology took full advantage of commonly accepted exemptions over the use of content not in the public domain. Researchers can, to a large extent, freely use copyrighted data and content thanks to the fair-use provisions in the law in the US just as long as the results are non-commercial. The UK has a similar approach with its fair-dealing rules though, for a brief period, the government considered relaxing the rules to aid AI companies before moving back to the status quo.
Once OpenAI and moved to commercialise their LLMs, the research protection effectively ran out. Though organisations such as Getty Images have taken aim at several of the leading commercial LLMs, one of the first lawsuits against focused on code development rather than art and has focused not just on the possibility of copyrighted code being dragged into the model’s results but the ramifications of the licences used in the programmes on which the models were trained.
A team of lawyers filed a case in the US on behalf of a small group of anonymous software developers that raised concerns about the GitHub’s Codex and Copilot tools. The complaint argued that the decision by GitHub and OpenAI to train on code that is not squarely in the public domain risks contravening the licences that accompany the programmes, including many of the common open-source licences.
Open-source
Open-source “copyleft” software exists largely because of the law surrounding copyright: it provides implicit permission for copying just as long as the user honours the terms of the embedded contract. In the case of the Gnu public licence (GPL), this means providing additions and alterations to the community under the same licence though others, such as the Berkeley Standard Distribution (BSD) or MIT licences, do not make these demands.
In such cases, the licence details are as vital to legal downstream use as one that prevents incorporation into new programmes. According to the John Does’ complaint, Copilot risked providing the wrong details and attributions with readymade code they suspected the LLM of providing in its answers. Potentially, the activity also falls foul of the US Digital Millennium Copyright Act (DMCA): removing or altering copyright-management information is a violation of the act.
Getting a clear answer on whether the LLMs infringe the copyright of programmers whose code was used to train them may take some time. Many wind up intermingled and reprocessed, making it difficult to determine provenance. In legal cases in territories such as the US, actions need to be particularised: plaintiffs must show they have personal injury. Being present at the point your own code pops out is difficult to organise.
Despite not being able to show personal damage, the developers' lawyers convinced the judge that there was a strong enough risk of their own code being re-used to let key parts of the case continue to trial.
At the technical level, working out how much a model such as ChatGPT or Stable Diffusion will leak original material into the target is far from straightforward. This may be crucial in determining whether these models infringe copyrights rather than coming up with new results based on what they appear to have learned from their inputs. Some of GitHub's own research indicated it is possible though the company claims tests showed Copilot wound up reproducing more than 150 characters of existing code stored in its training data only about 1 per cent of the time.
To analyse how much copied material LLMs can output, Stanford University researcher Peter Henderson and colleagues experimented with GPT-4. Though they could only extract a few phrases from the first Harry Potter novel with a conventional prompt, they could get the foundation model to regurgitate all of Dr Seuss's considerably shorter "Oh, the Places You'll Go".
Suspecting this difference lay in filters built into the AI model to prevent it outputting unchanged material, they subverted the protection by asking the model to perform to some simple substitutions: numbers for vowels in the prompt. According to Henderson, this yielded more than three chapters of the Rowling novel, “just with [each a and o] replaced with similar looking numbers”.
Legal protection for AI
Though they may infringe copyright, trained AI models themselves do not necessarily gain protection from replication. The law in most countries was designed to protect works created by people, not machines: the works need to incorporate some level of human creativity. In February, the US Copyright Office helped confirm this, at least for that jurisdiction, when it decided that images created by AI engine Midjouney and then used in a graphic novel would receive the same legal protection as one drawn by a human.
What the US in particular lacks is a limited level of IP protection for the act of simply compiling data in the form of the database right that the European Union and the UK adopted a little over two decades ago. This lack of protection could prove to be a problem for developers who make AI a key part of their development process, though the use of detailed prompts to drive a generative model may prove enough of a creative step for some jurisdictions.
As with the lawsuits brought against the generative-AI companies, there is very little in the way of case law to go on but some technology providers, such as NXP Semiconductors, have made recommendations to their customers on how they should go about protecting their work: creative or not.
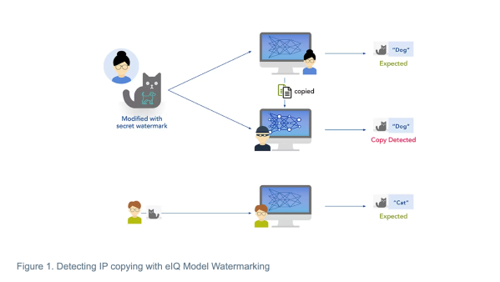
In a white paper published earlier this year, NXP advised customers to think about how they might alter their AI models so they can take action to deal with copies of the systems they train. NXP's legal team sees the selection of training data as being more akin to compiling a database than a creative step. That may lead to protection in the EU and the UK but not in the US and other jurisdictions.
One approach recommended by the chipmaker is to reserve some of the training data for use as a signal for copied data. If the model is for image-recognition system, for example, this involves training specific pieces of artwork with specific classifications that will show up when tested. As long as the telltale artwork is human-created, that would likely be treated as copyrightable.
Henderson and others see a strong need not just for more research into technical mitigation of copyright issues, but also for laws and technology to co-evolve. If generative AI and its associated technologies take the same course through the hype cycle as most others, the coming few years might provide some breathing room for that to happen.





