VLSI design became feasible without massive investment in full-custom design following the publication of the seminal book on chip design written by Carver Mead and Lynn Conway.
Many companies turned to the gate array as a cheaper alternative to the more flexible but harder-to-adopt standard-cell flow. But as mask costs spiralled because of the need to adopt increasingly exotic optical techniques to keep Moore’s Law on-track, the lower density of the gate became its weakness. If you were going to employ an ASIC, you might as well make it worth your while and go with the denser standard-cell option if not full- or structured-custom designs.
The gate-array users either made do with off-the-shelf parts or turned to field-programmable gate arrays (FPGAs) that pushed up unit costs but dispensed with a huge chunk of non-recurrent engineering (NRE) cost.
Luminaries such as UC Berkeley professor David Patterson believe custom chip design is making its way back to the lower-volume customer base that abandoned the hardwired gate array two decades ago.
In a series of speeches that kicked off with a Turing Award lecture to honour his work alongside Alphabet chairman John Hennessy in writing another engineering hit from the 1980s, “Computer Architecture - A Quantitative Approach”, Patterson talked of democratising design. He argued a number of elements have come together to yield more accessible and agile hardware.
“It’s a great time to be in hardware again. With agile hardware, everybody can do it and can afford it.”
In an environment where estimates for the cost of getting a 7nm system-on-chip (SoC) to market now run to more than $300m, claims of a mass move to custom hardware may seem incredible. People like Patterson are not thinking of those projects but smaller microcontroller-like designs that can be fabbed on older processes, such as 90nm, 45nm or 28nm.
“You can go a long way with small chips,” he argues.
Using multiproject wafers to cut mask costs and taking advantage of cheaper tools, the costs become much more manageable, similar to the gate arrays of yesteryear. Although custom hardware has its attractions, readymade silicon still has benefits. Assuming the parts are on the market, programmers can start with software on an evaluation board while the hardware team puts together the PCB design. The downside is that customisation is limited to what can be wrapped around the outside in a separate FPGA or what can be implemented in software.
The ASIC path provides the ability to change the core processor more fundamentally, either to add tightly coprocessors or even custom instructions.
Customisable instruction
Customisable instruction sets used to be restricted to a small subset of processor architectures, such as the Arc cores now owned by Synopsys and the Tensilica core family offered by Cadence Design Systems. Although suppliers of mainstream cores initially resisted the idea because of the threat customisation poses to compatibility, most have relented. The most recent was Arm with the option to add a limited set of custom operations to version 8 Cortex-M processors.
One reason for going down the custom route is energy.
Martin Croome, vice president of marketing at Greenwaves, says: “We are interested in devices that are really power constrained: systems that run for their entire useful lives from a single charge. By designing instruction-set extensions we can save three times the energy versus a device that uses the baseline processor architecture.”
Greenwaves opted for the RISC-V architecture, which provides an open-source instruction-set architecture and is steadily building an infrastructure of open-source development tools around it.
Croome say the customisation that his company has done “wasn’t possible before for a small start-up like ourselves”.
The drawback with custom silicon is the extra time that software engineers need to wait before they can start work on a stable prototype. Rocco Jonack, principal solutions architecture at German consultancy Minres Technologies, says it is often only during integration that mismatches between hardware are revealed.
In ASIC design, a common phrase in use today is the “shift left”: making it possible to begin software development and system verification much earlier and fix integration problems before the design has taped out to the fab. To get there, the teams employ virtual prototypes and hardware emulators of various forms.
Languages such as SystemC have made it easier to simulate architectures at a higher level and so run reasonably quickly on a workstation, although circuit-level emulation on a FPGA will be more accurate.
A major overhead even in SystemC simulation is the processor, as it is often the most complex circuitry in the system. The usual technique is to employ an instruction-set simulator (ISS) such as the open-source Qemu, which can be found in FPGA tools from suppliers such as Xilinx.
Working with an ISS with a limited set of simulated logic cores around it provides a mechanism for making faster progress in adding custom instructions, says Kevin McDermott, vice president of marketing at Imperas. Getting to the stage where you building a system and test it in an FPGA so it can work with live data raises problems:
“It’s months of work to prove your assumption,” he argues. “What happens if you find the advantage of adding instructions is not that clear cut. You want to let the software guys drive some of the early decisions.
“You want to know: does that instruction actually help? Can this function be achieved in one cycle? If I hard code this function will that be useful for the next four generations? It’s not enough simply to model.
“Communication is important. You want the software developers to talk to the hardware guys. Those conversations are going to be far faster than compiling to an FPGA and testing there,” McDermott says.
With an ISS and simulated data, it is a relatively fast process to add and modify custom instructions to test assumptions if it is not clear how much performance the extra hardware will provide.
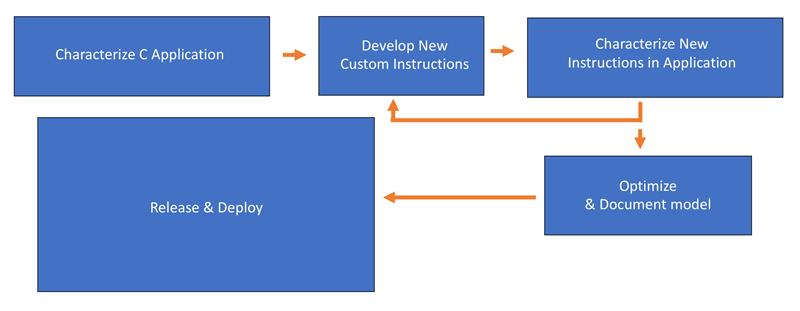
Above: A basic diagram showing a typical custom-instruction development flow
For example, it may be that the work that a custom instruction needs to do may work better in a coprocessor with its own memory interface as that avoids the need to load large quantities of data using core processor registers and displace other data that needs to be kept close to the core to maintain performance.
Another issue may be that a custom instruction is too inflexible to deal with algorithm changes that might be needed in later revisions.
Register-level interfaces to custom hardware are equally important. It may turn out that polling a register for changed state makes more sense than having a peripheral initiating interrupts whenever they finish a job because the function is in a highly active loop.
As simulations will help reveal the bottlenecks these decisions create or remove, Jonack says it is important to use high-level register-generation tools so these modifications can be made easily and quickly instead of diving into the RTL.
“We use a lot of automatic generation. Because these registers are constantly changing during the project.”
Techniques such as continuous integration supported by Jenkins and similar configuration tools help ensure hardware and software do not get out of step, Jonack says. With those approaches in place, it is possible to make embedded systems far more agile and support the ability to optimise hardware. In doing so, more teams should be able to exploit what Patterson calls a new golden age of architecture.





