
Not long from now, its founder and CEO Jen-Hsun Huang expects to preside over a company that reaches into every corner of the computing world thanks to a financial war chest the company built up from a strategy that saw its graphics processing units (GPUs) become the work horses of artificial intelligence (AI) in data centres.
Alongside the ability to handle many floating-point operations in parallel – an attribute needed for training deep neural networks – the main reason Nvidia's GPUs became more commonly used in data centres than competitors such as AMD lay in its CUDA environment. This is a strategy Nvidia aims to repeat following its acquisition of networking specialist Mellanox, coupled with some rebranding before it rounds out the portfolio with the addition of Arm and its general-purpose processor architectures.
But Huang is far from alone. A number of companies have seized on the idea of creating a novel class of processor and giving it a name: the data-processing data (DPU).
“We believe data centricity will drive next-generation architectures,” claimed Pradeep Sindhu, founder and CEO of Fungible, at HotChips 32 in August as the company prepared for the autumn launch of its own take on the concept.
The DPU is not an entirely novel concept: the architecture evolved from the Smart Network Interface Controller (SmartNIC) that began to appear in servers several years ago. Rather than attempting to load all the functions needed for a cloud application into individual server blades, the emphasis in computer design for data centres is on scaling out. Individual nodes run a small number of functions, typically called microservices, cooperating with each other in different ways to handle changing workloads.
Operations like search or data analytics can be split or in data-centre parlance "sharded" across tens, hundreds or thousands of servers or pushed down to smart disk drives.
The sharding provides the ability to support huge numbers of simultaneous users in a way that a smaller number of high-powered servers could not. But there is a catch.
“These new workloads put tremendous pressure on the network," Huang explained in his keynote at his company's autumn developers’ summit.
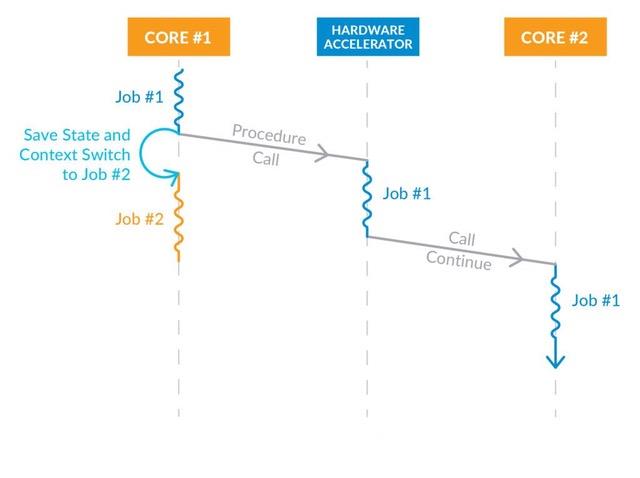
Above: Fungible-call-continue - in this model, tasks flow across the SoC as each function in a chain of tasks completes
More packets
This surge of internal traffic means each system has to deal with many more packets per second than conventional servers. On top of that, the machines have to handle the overhead of virtualisation in order to keep different customers' tasks separated as well as increasing use of deep packet inspection and other operations to protect against hacking.
Though all these functions can be run in software on the core processors, they eat into the overall cycle budget.
Huang says close to a third of the core processors' cycles can go into this packet handling infrastructure work rather than the application. SmartNICs made it possible to offload the simpler tasks. Now DPUs add more general-purpose processing abilities, often in the form of multiple Arm cores able to run Linux in concert with specialised packet, search and security coprocessors that handle the burgeoning packet-handling jobs.
Rather than Arm, Fungible picked MIPS64 as its main processor architecture, though Sindhu notes the company is not wedded to a particular instruction set architecture (ISA).
“This is a macro-architecture problem. There is a misunderstanding in the industry as to whether data-centric computations need a specific ISA.”
For most suppliers, the DPU is effectively a mashup of a multicore processor and a network switch armed with a collection of accelerators. At the Linley Group Fall Processor Conference, Marvell distinguished architect Wilson Snyder said almost a third of the die on its flagship DPU the CN98XX is given over to accelerators, sitting alongside six clusters of six custom-designed Arm processors, all connected to the I/O and each other using an x-y mesh with 1Tb/s of aggregate bandwidth.
The need to process data at speed that does not hang around for long has subtle effects on the architecture of the core processors. Marvell has several levels of cache in the CN98XX but the level-two cache, only stores instructions not data in contrast to most designs, which opt for a shared design.
"Because these applications deal with large amounts of data, the data keeps throwing out the instruction lines," Snyder says, which leads to slowdown, because instructions keep needing to be reloaded. "Some applications show more than a doubling in performance by having that instruction-only cache."
A further distinction from conventional multicore processors is how many of the cores that are allocated work. Though DPUs can generally run a multiprocessor Linux distribution much like a general-purpose processor much of the infrastructure around them is designed in concert with domain-specific software environments such as DPDK and the P4 programming language. P4 is designed around the flow generally used in packet processing, with an assumed flow based around parsing headers, breaking them into components to be matched and analysed before being reconstituted to be forwarded to a destination.
“We believe the P4 language is best-suited to describe these tasks,” says Francis Matus, vice president of engineering at SmartNIC specialist Pensando, adding that the company has defined hardware extensions that have fed into the open-source language.
The interdependence of hardware and software is illustrated by aspects such as task scheduling. For jobs that do not need special attention from more complex processes running on the Linux subsystems, DPU execution is generally based on run-to-completion, a technique used in some real-time systems to minimise task-switching overheads.
In this model, once a thread activates it runs without yielding the processor until it has finished its assigned work. On a single processor, this would impose severe delays on other threads waiting to start their own work. But in the context of a massive array of processors, schedulers can simply pick target cores based on criteria such as quality of service. Low-priority tasks can sit in a long queue while others are directed to those that are available to work more or less immediately.
Typically, a DPU associates each packet with a block of data that determines the sequence of jobs that need to be run on it.
Upcoming applications
Though SoCs at the SmartNIC end of the market are very much focused on packet routing and firewall operations, DPU vendors see a rich set of upcoming applications for the more advanced devices.
Changhoon Kim, CTO of applications in Intel's Barefoot division, points to the example of the GPU being redeployed for tasks such as AI. “We believe we will see the same kind of explosion of applications given the general-purpose programmability and high I/O capability of these P4 data-plane machines. You will see more I/O intensive compute-related applications emerging.
“One thing that some of our customers and Intel did together was deep-learning training acceleration,” Kim adds, noting that speedups in GPUs have not been followed by networking up to now, which causes bottlenecks for jobs such as sending neuron weight updates to individual GPUs running in a distributed setup.
A DPU can offload a lot of the data manipulation from the GPUs and more efficiently schedule updates. It can go further, he says, by having a DPU handle the allocation of work to the worker GPUs as well as rescaling data values on the fly and adding very large vectors that need to aggregate results produced by multiple workers. In one experiment, the data orchestration performed by the DPUs boosted training speed threefold, according to Kim.
To try to capitalise on a more general-purpose use of DPUs, Nvidia is using much the same approach as it did with GPUs. The CUDA equivalent in this case is called DOCA.
“The DOCA SDK lets developers write infrastructure applications for software-defined networking, software-defined storage and in-network computing applications yet-to-be-invented,” Huang says, adding that the company has not reinvented the wheel but incorporated P4 for packet processing and other widely used libraries.
In contrast to the situation with GPUs over the past couple of decades where there were a handful of suppliers, there is a lot more competition among DPU suppliers. Nvidia may find this environment harder to dominate.





