
Network metadata provides an overview of what is happening on a network without storing the entire payload, thus providing an effective, lossy compression. Along with timestamps and the amount of data transferred, this covers a lot of information; from IP source and destination addresses, to ports and protocol, right through to Secure Sockets Layer (SSL) certificates, Domain Name System (DNS) request/responses and HyperText Transfer Protocol (HTTP) host names.
A carrier scale network operator may be interested in a particular flow for a variety of reasons – for example, it may be malicious, and part of a cyber-attack.
What is vital is that metadata is extracted from every single packet; this is referred to as un-sampled traffic monitoring and the task is compounded by the fact that there is no single data pipe for the internet. There are literally billions of ingress and egress points, with routes that can be used by flows to get from an ingress to an egress. Furthermore, while there are typically several ‘cores’ to a carrier’s network, we now have edge computing, edge datacentres, cloud and mobile broadband in 3G, 4G and 5G, too.
Data rates are increasing exponentially, rising from 100GB per day in 1992 to a projected 150,700 GB per second in 2022. This means that there is continually more data to monitor between a growing number of devices. These figures highlight the need for higher rate network monitoring.
Data inspection
At full line rate, 4x100G Ethernet connections (as opposed to 1x400Gbps, which is a single network interface with a bandwidth of 400Gbps) can ingress up to 560 million packets per second. To give complete visibility, un-sampled traffic must be processed in real time; this is particularly important from a forensic evidence point of view.
Trying to find a single malicious flow amongst other malicious flows in 4x100GbE traffic can be like trying to find a needle in a haystack, with a box of other needles thrown in for good measure.
There are many software-based metadata extraction solutions available that can be installed on any commodity hardware, but this means they are also inherently rate limited by that commodity hardware. Typically, this would be several Gbps, or at a stretch 10Gbps.
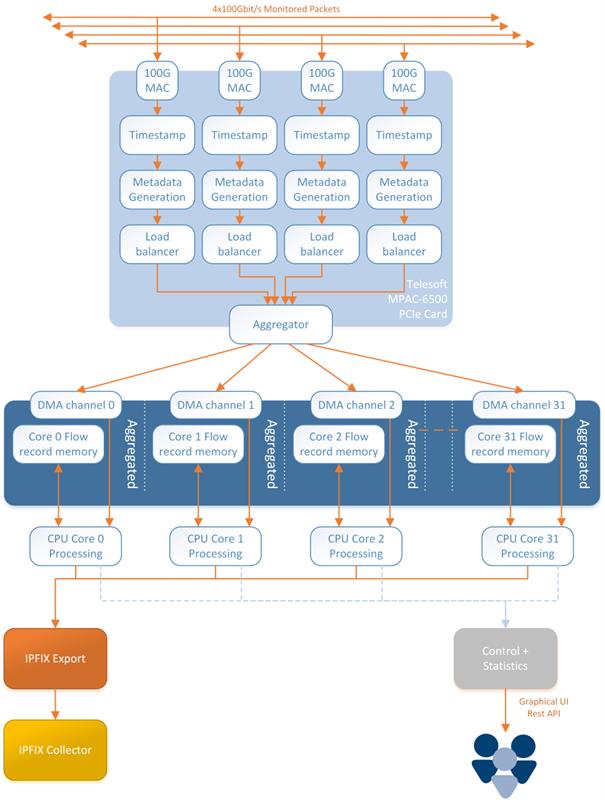
Figure 1: Global device and connections (Source: Cisco VNI, 2018)
Extracting network metadata at 4x100Gbps requires very high-speed processing, typically this can only be achieved using dedicated hardware, such as a Field Programmable Gate Array (FPGA) or an Application-Specific Integrated Circuit (ASIC). Both are used to accelerate calculations or processing and can remove system bottlenecks when used with processors, increasing the overall performance.
Faster results
Telesoft has shipped 100G Flow Probes since 2016 and has continued to increase the throughput and features ever since. Its 4x100GbE Flow Probe monitors networks in real time, generates un-sampled flows and is completely passive.
At the heart of the system is an Intel Stratix 10 FPGA, which receives the 4x100Gbps of network traffic and performs metadata extraction. The metadata is then passed to multiple processing threads where the packet metadata is combined into flows. Finally, the flows are enriched with additional information.
Packets are de-tunnelled in real time; if tunnelling is present then it is automatically detected, and the encapsulated traffic exposed. For complete visibility, in this case, the metadata for both the outer tunnelling protocol, and the encapsulated traffic within, is extracted.
The metadata extraction is feature-rich and extracts data from all layers of the Transmission Control Protocol (TCP)/IP model, right up to and including the application layer where HTTP request method, host, target and the status code are all sent up to the host. Furthermore, DNS packets are identified and forwarded on for the host to extract DNS flags, type and the domain name.
The Stratix 10 has been designed to meet the high-performance demands of high-throughput systems, such as Telesoft’s 4x100GbE Flow Probe, with transceiver support up to 28.3Gbps for chip-module, chip-to-chip and backplane applications; as well as up to 10 TFLOPS of floating-point performance. To enable high-speed host data processing, the metadata is delivered to the host over multiple Direct Memory Access (DMA) queues. Each queue is independently serviced by a dedicated host thread. The FPGA performs bi-directional flow-safe load balancing across the DMA queues, thus ensuring that all packets associated with any given uni-directional or bi-directional flow are delivered to the same host processing threads.
The host performs additional processing of the packet metadata to enrich the flow records with additional metadata. As an example, the host can perform a lookup of IPv4 / IPv6 address ranges against a live programmed tree of Classless Inter-Domain Routings (CIDRs) that provide Geo-Location, AS and IP reputation metadata. As each of these factors have temporal sensitivity it is essential that these matches are performed at the point of ingest.
The Stratix 10 GX devices are built on Intel’s 14nm tri-gate process and have a tiled architecture such that the chip itself is comprised of several smaller chips, or tiles. The logic is on one, monolithic die, while the transceivers are on separate tiles in groups of 24 channels; this architecture results in the highest transceiver count of any FPGA (with 144 full duplex channels). Intel has different varieties of transceiver tiles, some of which, alongside the transceiver channels themselves, have PCIe Gen3 x16 hard IP, as well as some with 100G Ethernet MAC hard IP – both of which are used by Telesoft in its flow probe.
Hardened IP enables developers to use these interfaces without worrying about whether they will meet performance requirements. In addition, there is no need to use FPGA logic in the device to implement these IP blocks, meaning it can be used for other features. The tiled architecture is made possible by the use of Intel’s innovative Embedded Multi-Die Interconnect Bridge (EMIB) packaging technology.
The differentiating factor
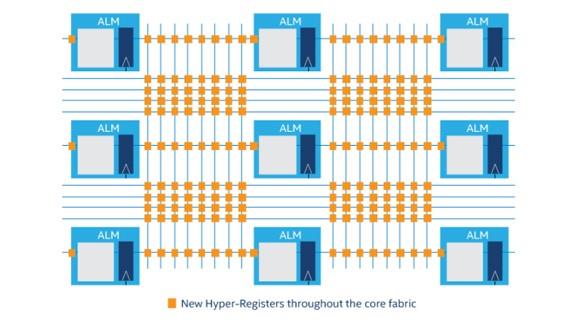
A Stratix 10 GX devices feature Intel's Hyperflex architecture, which introduces additional, bypassable, registers throughout the FPGA fabric. These registers, called Hyper-Registers, exist on every interconnect routing segment and at the inputs of all functional blocks (logic blocks, memory blocks and DSP blocks); they are also distinct from the conventional registers that are contained within the Adaptive Logic Modules (ALM).
These Hyper-Registers mean an FPGA designer can retime registers to eliminate critical paths, adding pipeline registers to remove routing delays. This approach also means that all of the FPGA’s logic resources are available for logic functions, instead of being sacrificed as feed-through cells in conventional architectures. The design tools can select the optimal register location automatically as well as reducing routing congestion.
Conclusion
Networks are complex environments, where speed and performance are measured in the smallest fractions of a second. The threat presented by a connected world relies, to some extent, on hiding in plain sight, due to the deluge of data that enters into, flows through and exits the many millions of networks found around the globe.
Metadata is a crucial tool in combating this threat, and flow probes are the practical implementation of that tool. Through the performance offered by integrated solutions like the Intel Stratix 10 GX FPGA, and Telesoft's ingenuity, networks are safer for all users.
Author details: Richard Parks is FPGA Team Leader at Telesoft and Claire Huckerby-Brown is a Field Applications Engineer at Intel.





