
Digital lifestyles and the emerging IoT are inextricably connected with the rapid growth of computing and data services in the cloud and 5G New Radio (NR) will place intense pressure on the capacity and performance of backhaul, metro, and core networks.
There is strong demand for increased data bandwidth and compute throughput across cloud data centres and in telecom and cellular-backhaul networks, touching key components including the links into and out of data centres, data centre interconnects (DCI), infrastructure interface cards, and accelerator cards.
Building new and higher performing equipment to meet these demands using discrete components will increasingly be unable to scale with performance demands. Next-generation equipment is going to have to deliver significantly increased performance within existing physical, electrical, and thermal boundaries.
In addition, design work needs to begin using the latest protocols and standards before the final specifications are agreed, in order to be market ready at the earliest possible opportunity. Waiting for specifications to mature is not an option for equipment providers, so flexibility to adapt at a hardware level as the project progresses will be required.
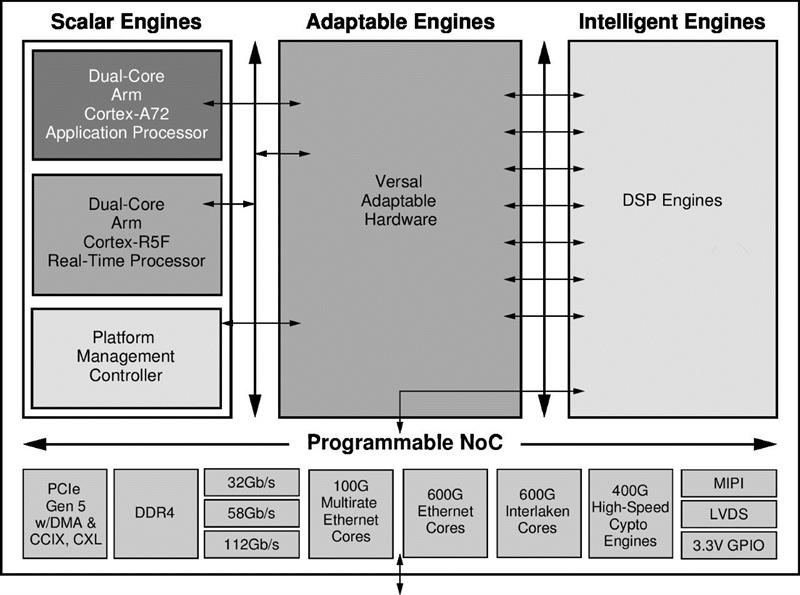 Figure 1: Versal Premium ACAP with 112Gb/s PAM4, 600G Ethernet, 600G Interlaken, and 400G HSC
Figure 1: Versal Premium ACAP with 112Gb/s PAM4, 600G Ethernet, 600G Interlaken, and 400G HSC
Game-changer
Programmable logic devices such as high-density FPGAs and programmable System-on-Chip ICs (MPSoCs) have become the accelerator of choice for workloads that cannot be executed quickly enough in conventional CPU or GPU architectures or do not satisfy power constraints. Offering a high degree of parallelism to offload specific compute challenges these also provide inherent adaptability as programmable devices.
Now, to satisfy more recent and more demanding performance, bandwidth, power, and integration targets, a new class of programmable devices called Adaptive Compute Acceleration Platform (ACAP) has emerged.
The Xilinx Versal ACAP contains an array of intelligent AI and DSP compute engines, adaptable engines equivalent to FPGA logic fabric, and application-processing and real-time scalar engines, closely coupled through a programmable Network on Chip (NoC) interconnect.
Software-controlled platform management and state-of-the-art interfaces including DDR4, 100G Ethernet, PCIe Gen 5, and multi-gigabit optical interfaces are also integrated.
The Versal DSP engines feature improved DSP blocks with native support for operands such as INT8, 32-bit floating point, and others, to increase the speed and efficiency of applications that include not only digital signal processing but also wide dynamic bus shifters, memory address generators, wide bus multiplexers, and memory-mapped I/O registers. The scalar engines comprise a dual-core Arm Cortex-A72 application processor and dual-core Arm Cortex-R5F real-time processing unit.
The ACAP’s heterogeneous engines can be reprogrammed to adapt to workloads that change over time, or as algorithmic implementations or neural-network models evolve.
These high-bandwidth devices combine high compute density with additional dedicated high-speed cryptographic (HSC) engines and state-of-the-art network interfaces.
The intensive network connectivity includes scalable optical transceivers up to 9Tb/s total bi-directional bandwidth supporting the latest Ethernet and Interlaken rates and protocols, 112Gb/s PAM4 transceivers, and cryptographic processing with up to 400Gb/s high-speed crypto engines, and adaptable hardware, (See Figure 1).
Compared to existing 58Gb/s PAM4 technology, using 112G PAM4 transceivers allows a doubling of bandwidth density per port, easing pressure on front-panel rack space and allowing a doubling of bandwidth per unit volume in Telco and data centre applications.
At the same time, the latency for transmitting a given payload of data is 50% lower, which enables applications to be more responsive and helps mitigate latency impacts when interconnecting geographically distributed data centres.
The resources integrated on-chip provide up to three-times the bandwidth and double the compute density of Xilinx’s 16nm Virtex UltraScale+ FPGAs while, when compared to a dedicated application-specific OTN (optical transport network) processor, application-throughput capability is three to five times greater.
Increase in compute density
To meet the demands of hyperscale cloud service providers, the Versal ACAP architecture combines high on-chip memory bandwidth tightly coupled to high performance heterogeneous compute engines with flexible workload provisioning through Dynamic Function eXchange (DFX).
With the ability to swap kernels eight times faster than preceding 16nm FPGAs, DFX permits dynamic provisioning of accelerators to make the most efficient use of device resources for compute workloads that change over time.
With multiple types of distributed RAM on-chip, up to 1Gb of tightly coupled memory is available, having equivalent on-chip memory bandwidth of up to 123TByte/s. This enables high-speed interactions between the various processing engines and memory and, in addition, the programmable NoC interconnect supports high-speed interaction with off-chip DDR4 memory.
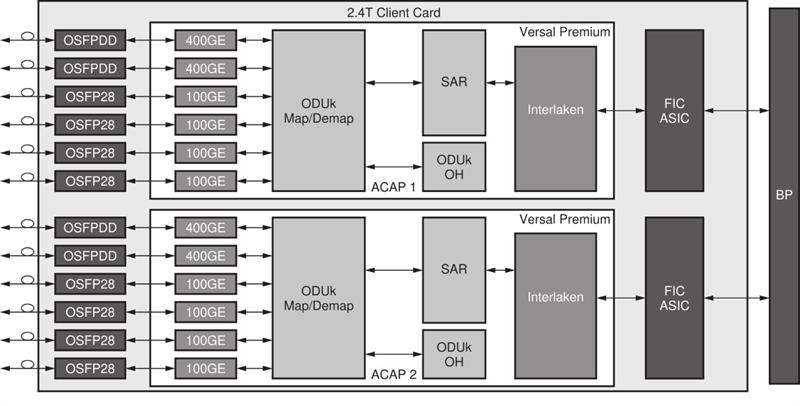
Versal Premium ACAPs can meet demands for DCI equipment to accommodate a variety of server-side and transport-side optics and protocols while remaining free to adapt to emerging and evolving standards in a secure, cost efficient platform.
A 1RU system or a single card can be built to provide 3.2Tb/s capacity with support for a wide variety of standardised and emerging protocols and optics. A single Versal Premium ACAP, with its state-of-the-art connectivity and cryptographic cores, can implement multiple channels of 100G FlexE Ethernet with 4x25G NRZ connections to optics on the server side, 400G Ethernet channels on the line side implemented with 4x112G PAM4 connections, AES256 encryption at 1.6Tb/s line rate, and control and port-management functions.
These devices are intended for high-speed client interface cards (Figure 2), and leveraging Versal to bridge and encapsulate digital traffic and services into industry-standard OTN wrappers. The integrated channelized Ethernet, Interlaken, and 112G and 58G PAM4 GTM transceivers and 32.75G GTYP transceivers provide multi-terabit/s capacity. These resources, being integrated as dedicated hard IP, enable ASIC-class power efficiency while leaving the ACAP logic fabric free for mapping, overhead, and SAR functions.
Future-proof AI acceleration
The combination of heterogeneous compute engines and high memory bandwidth allow Versal to deliver a significant performance boost over GPUs when handling tough workloads such as image classification or object detection with neural networks.
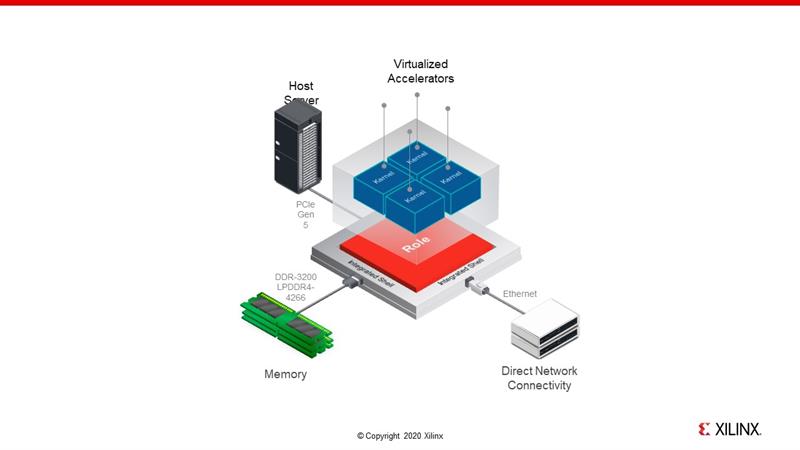
Another interesting feature of the ACAP that simplifies accelerator development, compared to FPGA and MPSoC architectures, is the pre-built shell that provides hard connections to off-chip interfaces such as Ethernet, PCIe Gen 5, DDR4, and optical interfaces. This efficient infrastructure for cloud connectivity delivers several advantages including allowing CPU host and system memory communication to be available at device start-up, as well as simplifying kernel placement and timing closure and simplifying accelerator virtualization. The shell allows designers to utilise more of the device’s internal logic fabric for custom functions, which would otherwise be required to implement necessary infrastructure such as memory and DMA controllers.
The shell and role architecture helps designers to implement advanced smart-retail technology quickly and efficiently in Versal Premium ACAPs.
The devices can support data-driven video content analytics that can help mitigate losses and offer automated, real-time and actionable insight into inventory, as well as the ability to tailor customer experiences to maximize sales. With Versal Premium ACAP, it is possible to host a video analytics solution on a single platform for identification, extraction, and classification of video metadata.
The shell provides off-the-shelf connectivity and cryptography, while the device’s DSP engines and software-programmable compute kernels handle object detection and image classification as well as video encoding, decoding, and scaling. Up to 1Gb of on-chip SRAM is available immediately adjacent to the compute kernels, providing up to 123TB/s of memory bandwidth for AI acceleration. By eliminating the memory-bottleneck and batch-size limitations that hinder GPU and CPU-based architectures, an analytics accelerator can operate at up to 13,000 images/sec for Resnet50.
As the world becomes increasingly data centric, and relies on instant service delivery, however complex, compute intensive, and bandwidth sapping, the ACAP is able to provide a combination of efficient, distributed heterogeneous compute engines and high-speed interconnect to meet rapidly increasing performance demands.
By blending hard IP, an innovative pre-built connectivity shell, and programmable logic fabric, and software-configurable resources, these devices not only boost performance but also simplify design and provide future-proof flexibility.
Author details: Mike Thompson, Sr. Product Line Manager, Virtex UltraScale+ FPGA and Versal Premium ACAP at Xilinx





