
Artificial intelligence (AI) is now seen as a vital technology for the development of the Internet of Things (IoT) and cyber-physical systems such as robots and autonomous vehicles.
The smart speaker provides an example of advanced AI in action in everyday life through its ability to recognise natural language and synthesis high-quality speech. To do so, the speaker needs to pass data on to multiple high-speed computers in remote server farms. The embedded hardware is seen as being too limited to be able to run the kinds of deep neural network (DNN) algorithms on which they rely.
AI need not be limited to deployment in high-powered computing engines located in server farms. AI techniques are now also being proposed as a way of managing the immensely complex 5G New Radio protocol. The number of channel parameters that need to be analysed by handsets to deliver optimum data rates have outpaced the ability of engineers to develop efficient algorithms. Algorithms trained on data obtained during field trials provides a way to balance the trade-offs between different settings more efficiently.
When it comes to maintaining the health of industrial equipment operating in remote locations, machine-learning algorithms running on embedded hardware are becoming an effective option. Traditional algorithms such as Kalman filters readily deal with linear relationships between different types of input data such as pressure, temperature and vibration. But the early warnings of problems ahead of problems are often identified by changes in relationships that can be highly non-linear.
AI implementations
Systems can be trained on data from healthy and failing machinery to spot potential problems when fed with real-time data. However, a neural network, though a popular choice today, is not the only AI solution available. There are many algorithms that can be applied and an alternative solution may be the most appropriate for the task at hand.
One possible solution can be found in rule-based AI. This leverages the expertise of domain experts rather than direct machine learning by encoding the experts’ knowledge within a rule base. An inference engine analyses the data against the rules and attempts to find the best match for the conditions it encounters. A rule-based system has low computational overhead but developers will encounter difficulties if the conditions are difficult to express using simple statements or the relationships between input data and actions are not well understood. The latter situation, which applies to speech and image recognition, is where machine learning has been shown to excel.
Machine learning is closely related to optimisation processes. Given input database elements, a machine-learning algorithm will attempt to find the most appropriate way of classifying or ordering them. A curve-fitting algorithm based on a technique such as linear regression can be considered as being the simplest possible machine-learning algorithm: one that uses the data points to formulate the best-fitting polynomial that can then be used to determine the most likely output for a given input datum. Curve fitting is only appropriate for systems with very few dimensions. True machine-learning applications can deal with complex high-dimension data.
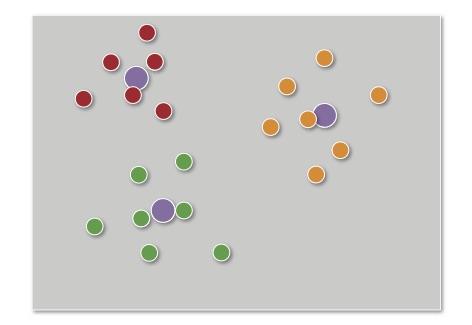
Above: Clustering uses mechanisms such as distance from the nearest centroid to divide data |
Clustering goes further by classifying data into groups. A typical algorithm is one based on centroids but many other types of cluster analysis are used in machine learning. A centroid-based system uses geometric distance between data points to determine whether they fall within one group or another. Cluster analysis is often an iterative process in which different criteria are applied to determine where boundaries form between clusters and how closely related data points within a single cluster need to be. However, the technique is effective for demonstrating patterns in data that might elude domain experts. Another option for separating data into classes is the support vector machine (SVM), which divides multi-dimensional data into classes along hyperplanes that are created using optimisation techniques.
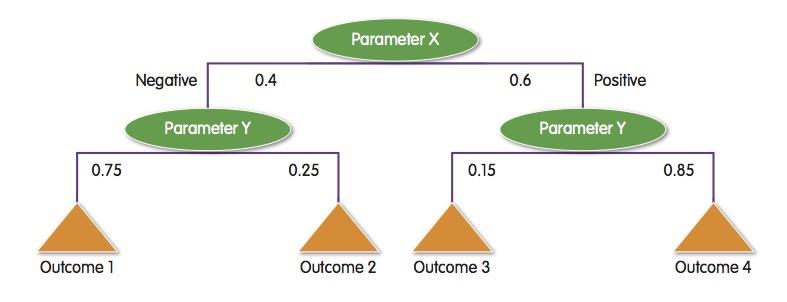
The decision tree provides ways to use clustered data in a rule base. A decision tree provides a way for the AI algorithm to work through data inputs to develop an answer. Each branch in the tree may be determined by cluster analysis of input data. For example, a system may behave differently above a certain temperature such that a pressure reading that is acceptable in other conditions may help indicate a problem. A decision tree can use these combinations of conditions to find the most appropriate set of rules for the situation.
Although DNNs generally require high-performance hardware to run in real time, there are simpler structures such as adversarial neural networks that have been successfully implemented on mobile robots based around 32bit or 64bit processors such as those found in the Raspberry Pi platforms. The DNN’s key advantage lies in the large number of layers it employs. The layered structure makes it possible for neutrons to encode connections between multi-dimensional data elements that may be highly separated in space and time but which have important relationships that are revealed during the training process.
As well as its computational overhead, a drawback with the DNN is the huge amount of data that is needed to train it. This is where other algorithms such as those based on Gaussian processes are now being investigated by AI researchers. These use probabilistic analysis of data to build models that function in a similar manner to neural networks but which use far less training data. However, in the short term, the success of the DNN makes it a key candidate for dealing with complex multi-dimensional inputs such as images, video and streaming samples of audio or process data.
One option in applications with complex requirements may be to use a simple AI algorithm in the embedded device to look for outliers in the input data and then request services from the cloud to look at the data in more detail to provide a more accurate answer. Such a split would help maintain real-time performance, limit the amount of data that needs to be transmitted over long distances and ensure continuous operation even in the face of temporary network outages. If a connection is lost, the embedded system can cache the suspicious data until an opportunity arises to have it checked by a cloud service.
Below: Decision trees provide a way to structure data based on classification rules and associated probabilities of different outcomes |
AI providers
Amazon Web Services (AWS) and IBM are among the companies that now offer cloud-based AI services to their customers. AWS provides access to a wide range of hardware platforms suitable for machine learning, including general-purpose server blades, GPU accelerators and FPGAs. The DNNs run in the cloud can be built using open-source frameworks such as Caffe and Tensorflow that are now widely used by AI practitioners.
IBM has built direct interfaces to its Watson AI platform to boards such as the Raspberry Pi, making it easy to prototype machine-learning applications before committing to a final architecture. ARM provides a similar link to Watson through its mbed IoT device platform.
Although AI may seem like a new frontier in computing, the availability of high-performance boards at low cost such as the Raspberry Pi and access to cloud-based machine-learning services mean embedded developers have straightforward access to the full gamut of machine-learning algorithms that have been discovered over the past few decades. As more sophisticated techniques are developed, the combination of onboard processing and cloud computing will ensure embedded developers can stay abreast of them and deliver the smartest solutions possible.
 Author details Cliff Ortmeyer is Global Head of Technical and Commercial Marketing, Premier Farnell |





